Il web semantico è un'estensione del World Wide Web in cui i documenti pubblicati (pagine HTML, file, immagini, e così via) sono associati ad informazioni e dati (metadati) che ne specificano il contesto semantico in un formato adatto all'interrogazione e all'interpretazione (es. tramite motori di ricerca) e, più in generale, all'elaborazione automatica.
Con l'interpretazione del contenuto dei documenti che il Web semantico impone, saranno possibili ricerche molto più evolute delle attuali, basate sulla presenza nel documento di parole chiave, e altre operazioni specialistiche come la costruzione di reti di relazioni e connessioni tra documenti secondo logiche più elaborate del semplice collegamento ipertestuale. Il termine è stato coniato da Tim Berners-Lee, inventore del Web.[1]
Introduzione
Per la sua costruzione/definizione, si potrebbe pensare di utilizzare l'XML, un metalinguaggio che consente di descrivere (e con il dettaglio desiderato) le diverse parti di un documento. Un documento così descritto può poi essere elaborato per usi diversi: estrazione di informazioni secondo specifici criteri, riformulazione più o meno parziale per l'adattamento ad altri formati, visualizzazione in funzione delle capacità del terminale. XML però non consente una definizione semantica adeguata, per motivi che specificheremo dopo.
Sebbene un documento sia un buon modo per specificare informazioni, un documento, ancorché espresso in formato XML, è poco adatto al Web che, per sua natura, è distribuito e decentralizzato e, quindi, informazioni su una particolare entità possono essere localizzate ovunque.
Infatti, con XML è possibile descrivere adeguatamente i contenuti di un documento, ma la sintassi XML non definisce alcun meccanismo esplicito per qualificare le relazioni tra documenti. In questo non è di aiuto neppure il meccanismo dei collegamenti ipertestuali reso popolare dall'HTML perché amorfo, cioè non prevede la possibilità di descrivere il legame definito.
In altre parole, sebbene in un documento (ad es. una pagina HTML) sia possibile parlare di un Signor Ciampi ed esprimere semanticamente questo con opportuni tag, è poi difficile capire se due documenti che parlano di un Signor Ciampi si riferiscano alla stessa persona, con conseguente scarsa qualità dei risultati restituiti dai motori di ricerca.
Nella migliore delle ipotesi sarebbe possibile dedurlo se, tra gli altri, vi fossero dati anagrafici semanticamente definiti e sufficientemente precisi (ad es. il Codice Fiscale) o collegamenti ipertestuali debitamente descritti che li collegano.
Poiché, però, i diversi documenti sono redatti per scopi differenti, indipendentemente gli uni dagli altri e normalmente senza condividere un comune formato XML, informazioni utili quali l'indirizzo postale o la data di nascita finiscono per essere espresse in modo dissimile e non uniforme. L'indirizzo in un caso può essere semplicemente racchiuso dal tag <indirizzo>, in altri da <indirizzo_postale>, <direccion>, <address> o <adresse>, e poi è da considerare la possibilità di avere esplicitamente identificati <via>, <numero_civico>, ... rendendo ardua e non priva di rischi ogni deduzione automatica.
Nei prossimi paragrafi si illustreranno prima il linguaggio utilizzato per costruire il web semantico, quindi le previste evoluzioni, gli strumenti e il contributo che queste tecnologie potrebbero dare per rispondere definitivamente ad uno dei problemi irrisolti in ambito informatico: la gestione della conoscenza.
I primi linguaggi: RDF, N3
L'evoluzione del web in web semantico inizia con la definizione, da parte del W3C, dello standard Resource Description Framework (RDF), una particolare applicazione XML che standardizza la definizione di relazioni tra informazioni ispirandosi ai principi della logica dei predicati (o logica predicativa del primo ordine) e ricorrendo agli strumenti tipici del Web (ad es. URI) e dell'XML (namespace).
In estrema sintesi, secondo la logica dei predicati le informazioni sono esprimibili con asserzioni (statement in inglese) costituite da triplette formate da soggetto, predicato e valore (in inglese spesso identificati come subject, verb e object, rispettivamente). Ad esempio, le seguenti affermazioni su un Presidente della Repubblica italiano:
Il Signor Ciampi vive a Roma.
Il Signor Ciampi ha codice fiscale CMPCLZ20T09E625V.
possono essere schematicamente scomposte come
Asserzione 1
Asserzione 2
Soggetto
Il Signor Ciampi
Il Signor Ciampi
Predicato
vive a
ha codice fiscale
Valore
Roma
CMPCLZ20T09E625V
allora, per alcuni di questi elementi, è possibile reperire arbitrariamente sul WebURI (risorse) che li identificano univocamente quali:
Il Signor Ciampi si è scelto di referenziare la relativa biografia disponibile sul sito ufficiale del Quirinale
Roma si è scelto di utilizzare il sito istituzionale del Comune di Roma
vive a si è scelto di referenziare la definizione del verbo vivere disponibile su Wikizionario
ha codice fiscale si è scelto di referenziare la definizione di codice fiscale disponibile su Wikipedia
Nei prossimi paragrafi si descrive come formalizzare le precedenti frasi in RDF nella sua forma canonica, in due suoi formati testuali alternativi (N3 ed N3 con prefissi) e graficamente.
Si segnala che appositi programmi come IsaViz[2] del W3C consentono di passare da un formato all'altro e sono utili per la sperimentazione del Web semantico.
Soluzione RDF canonica
Una possibile formalizzazione dell'esempio in RDF è:
rdf:RDF è il nodo radice di un documento RDF definito nel namespacerdf di cui alla Riga 3
Riga 3
xmlns:rdf= referenzia il namespace standard della sintassi RDF, identificandolo come rdf. Si ricorda che in XML si definisce un namespace per rendere più sintetica la scrittura del codice. D'ora in poi, infatti, ogni volta che si incontra rdf: lo si deve (mentalmente) sostituire con quanto scritto a destra dell'= di questa espressione, come già fatto nella Riga 2.
Riga 4 e 5
xmlns:wikipedia= e xmlns:wikizionario= referenziano due ulteriori namespace, identificandoli come wikipedia e wikizionario
Righe 6-11
Definiscono l'asserzioneIl Signor Ciampi vive a Roma
Riga 6
rdf:Description è il tag del namespace rdf di cui alla Riga 3 che consente di specificare un'asserzione (soggetto, predicato, valore)
Riga 7
rdf:about è un attributo dell'elemento Description di Riga 6 da utilizzare per specificare il soggetto di un'asserzione quando, come in questo caso, è un URI
Il signor Ciampi
Riga 8
vivere è il tag definito nel namespace wikizionario di cui alla Riga 4, utilizzato per definire il predicato
vive a
Riga 9
rdf:resource è un identificativo del namespace rdf di cui alla Riga 3 per specificare il valore dell'asserzione, quando espresso come URI
Definiscono l'asserzioneIl Signor Ciampi ha codice fiscale CMPCLZ20T09E625V
Riga 12
rdf:Description è il tag del namespace rdf di cui alla Riga 3 che consente di specificare un'asserzione (soggetto, predicato, valore)
Riga 13
rdf:about è un attributo dell'elemento Description di Riga 12 da utilizzare per specificare il soggetto di un'asserzione quando, come in questo caso, è un URI
Il Signor Ciampi
Riga 14
'codice_fiscale è il tag definito nel namespace wikipedia di cui alla Riga 4, utilizzato per definire il predicato
Ha codice fiscale
Riga 15
Il valore dell'asserzione
CMPCLZ20T09E625V
Riga 16
Chiude l'elemento aperto alla Riga 14
Riga 17
Chiude il tag Description aperto alla Riga 12
Riga 18
Chiude l'elemento radice RDF aperto alla Riga 2
Poiché le due frasi hanno lo stesso soggetto, allora possono essere riformulate nella seguente:
Il Signor Ciampi vive a Roma ed ha Codice Fiscale CMPCLZ20T09E625V
alla quale corrisponde una formalizzazione RDF altrettanto sintetica (ed equivalente alla precedente):
Per rappresentare graficamente asserzioni RDF, si utilizzano i grafi scegliendo i nodi per soggetto e valore, uniti da un arco orientato da soggetto a valore per il predicato.
Alcuni applicativi, come il già citato IsaViz, utilizzato in quest'esempio, adottano ellissi per i nodi che sono URI (http://www.comune.roma.it/index.asp), altrimenti dei rettangoli per i nodi che contengono semplici stringhe di caratteri (CMPCLZ20T09E625V). Detto ciò, al nostro esempio corrisponde il grafo:
Grafo RDF dell'esempio generato con il tool IsaViz
Soluzione N3
N3 (noto anche come N-triples o Notation 3) propone una forma più facile da leggere rispetto ad RDF e l'esempio che stiamo considerando trova la seguente soluzione:
Ciascuna asserzione può essere scritta anche su un'unica linea, mettendo soggetto, predicato e valore l'uno di seguito all'altro. Si ricorda che in N3 è significativo anche il . (punto) che contrassegna la fine di ciascuna asserzione.
Soluzione N3 con prefissi
N3 con prefissi (N3 with prefix nella dizione inglese) è ancor più sintetico di N3 e riprende l'idea dei namespaceXML per agevolare la compilazione utilizzando dei semplici editor. In questo caso l'esempio è tradotto come:
Dove con il comando @prefix si definiscono costanti di sostituzione che specifici strumenti automatici si occupano di operare per completare le asserzioni che le utilizzano. Così come per N3, anche per N3 con prefissi è significativo il . (punto) alla fine di ciascuna asserzione.
OWL
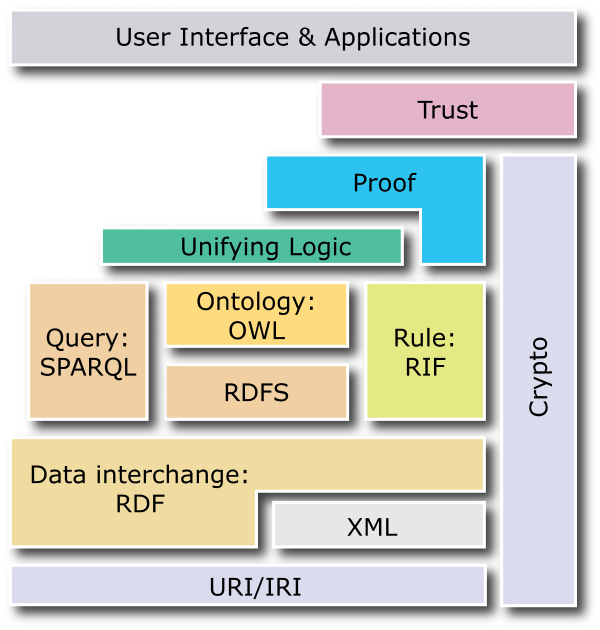
RDF non è che il primo passo. Il web semantico lo si sta costruendo a strati:
La logica predicativa del primo ordine è estremamente complessa, e RDF ne poteva esprimere una porzione molto ristretta. Non solo: questa logica, se presa complessivamente, non è nemmeno computabile, mentre possono essere computabili delle logiche costituite da sottoinsiemi degli operatori della logica del primo ordine. Questi sottoinsiemi della logica formale sono studiati dalle logiche descrittive, o description logics, ed una di queste è stata adottata per la formulazione di un nuovo standard, più ricco ed espressivo di RDF: OWL.
OWL offre molti nuovi costrutti, due di questi, molto semplici da comprendere, sono l'equivalenza tra risorse e la relazione inversa.
Per equivalenza tra risorse si intende la possibilità di affermare che due o più URI rappresentano lo stesso elemento.
Per inversa si intende la possibilità di dire che se è vero (soggetto, predicato, oggetto), allora è anche vero (oggetto, predicato_inverso, soggetto).
L'importanza di un costrutto come l'equivalenza è presto spiegata anche solo considerando gli esempi fatti in precedenza. Ad es. poter dichiarare che
CF:CMPCLZ20T09E625V, wikipedia:carlo_azeglio_ciampi e quirinale:ciampi.htm
sono equivalenti
consentirebbe di capire che le asserzioni
CF:CMPCLZ20T09E625V si chiama "Carlo Azeglio Ciampi"
wikipedia:carlo_azeglio_ciampi vive a Roma
quirinale:ciampi.htm è un "Presidente della Repubblica"
debitamente formalizzate ed ovunque reperite si riferiscono alla stessa risorsa, un Presidente della Repubblica (qualsiasi cosa questo significhi, ovvero qualsiasi cosa possa essere inferito da questa informazione) che vive aRoma e si chiamaCarlo Azeglio Ciampi.
Per quanto riguarda l'inversa, invece basta pensare che quando si afferma che Romolo è fratello di Remo, si intende anche che Remo è fratello di Romolo, asserzione da fare esplicitamente in RDF per poter essere nota al sistema. Operazione fattibile ma tediosa. Per ovviare a ciò, sarebbe sufficiente poter definire una volta per tutte che se X è fratello di Y allora è vero anche Y è fratello di X.
Questi costrutti, insieme ad altri, sono stati introdotti per primi da linguaggi precedenti o contemporanei ad RDF quali DAML (definito dall'americana DARPA) ed OIL (sponsorizzata dalla Unione europea nell'ambito del programma IST), successivamente confluiti in DAML+OIL. Su questa base il W3C ha definito OWL (Web Ontology Language).
OWL esiste in tre forme, caratterizzate da diversi gradi di complessità e - conseguentemente - di computabilità. OWL-Lite è computabile (ossia è possibile trovare tutte le soluzioni in un tempo finito) ma poco espressivo; OWL-Lite è poco usato, poiché esiste OWL-DL, che è ugualmente computabile ma più ricco. Infine esiste OWL-Full, che copre tutta la ricchezza della logica predicativa, ma non è computabile e non è quindi adatto al ragionamento automatico.
Con OWL è possibile scrivere delle ontologie che descrivono la conoscenza che abbiamo di un certo dominio, tramite classi, relazioni fra classi e individui appartenenti a classi. La conoscenza così formalizzata è processabile automaticamente da un calcolatore, tramite un ragionatore automatico che implementa i processi inferenziali e deduttivi.
Modalità di impiego
Dagli esempi precedenti si evince che condizione necessaria per il buon utilizzo di RDF è la disponibilità on-line di riferimenti di qualità alle URI utilizzate/referenziate. In particolare, è importante che queste risorse siano note, condivise e stabili nel tempo. Ad esempio, il riferimento utilizzato per identificare il Presidente Ciampi, da questo punto di vista, non è dei migliori perché valido solo durante il mandato presidenziale, dopodiché sarà spostata in http://www.quirinale.it/qrnw/statico/ex-presidenti/Ciampi/cia-biografia.htm dove già si trovano quelle dei suoi predecessori.
Dopo questa data l'asserzione continuerà a valere, ma si perderà il contributo informativo apportato dalla pagina referenziata sul web utile per una interpretazione dello stesso.
Molto più opportuno sarebbe utilizzare la biografia definita in Wikipedia oppure il Codice Fiscale con, ad es.,
Sebbene questa URI oggi non referenzi alcunché sul Web, la si potrebbe comunque utilizzare allo scopo perché RDF non presuppone alcuna verifica sulla effettiva disponibilità della risorsa stessa. In questo modo tutte le persone fisiche e giuridiche contemporanee e non solo personaggi, aziende, enti ed istituzioni "importanti" potrebbero essere univocamente identificati, potenziando notevolmente le possibilità di RDF (in ogni caso nulla vieterebbe all'Agenzia delle entrate di mettere a disposizione un servizio che a partire dalla URI citata restituisca automaticamente le relative informazioni anagrafiche).
Un altro accorgimento da tenere presente nella scelta dei termini da utilizzare per la definizione delle relazioni è di ricorrere a dizionari già noti e diffusi, invece che inventarne ogni volta di nuovi. Ad es. per le informazioni anagrafiche personali tipiche dei biglietti da visita quali nome, cognome, indirizzo, e-mail, ruolo aziendale... è già disponibile vCard[4]. Non sono da dimenticare neppure le numerose applicazioni XML definite per abilitare l'EDI (Electronic Data Interchange, scambio dati elettronico) nell'ambito della pubblica amministrazione (e-government) o di associazioni di settore.
Da quanto esposto finora è facile intuire che, nella costruzione del web semantico, progetti come Wikipedia o Wikizionario non sono solo funzionali ma, adeguatamente sfruttati, anche abilitanti perché forniscono lemmi ben documentati per individuare risorse e predicati, garantendone la stabilità nel tempo e, grazie alla possibilità di dichiarare equivalenze nella stessa lingua e tra lingue diverse, di accrescere ulteriormente l'estensione di un'indagine automatica.
Strumenti
Ovviamente non è sufficiente avere solo una sintassi per esprimere predicati. Per rendere concreto ed utile quanto detto finora, occorrono anche strumenti in grado di gestire un insieme di asserzioni per rispondere alle richieste utente.
Per quanto riguarda N3, la gran parte di questi strumenti, come si può intuire dagli esempi di N3 ed N3 con prefissi, archivia le asserzioni in una o più tabelle di un database relazionale. Alcune di queste soluzioni sono state censite dal progetto SWAD-Europe sponsorizzata dall'Unione Europea nell'ambito dell'iniziativa ISTArchiviato il 22 giugno 2004 in Internet Archive..
Sui documenti scritti in OWL (o ontologie), invece, si può eseguire un vero e proprio ragionamento deduttivo inferenziale, realizzato tramite ragionatori automatici.
Linguaggi di query
Per utilizzare le basi di conoscenza formalizzate secondo questi standard è necessario un linguaggio per interrogarle. SPARQL (Simple Protocol And RDF Query Language) è uno dei linguaggi definiti per interrogare sistemi che gestiscono asserzioni RDF. Ad oggi sono disponibili altri linguaggi funzionalmente equivalenti ma SPARQL è candidato a divenire una raccomandazione W3C[5].
Per interrogare OWL, invece, manca ancora uno standard, ed i singoli ragionatori implementano linguaggi di query proprietari.
Web semantico e gestione della conoscenza
Da quanto detto si capisce perché se l'XML si rivolge alla descrizione di documenti, RDF (e sue evoluzioni) è particolarmente indicato per rappresentare dati, fornendo un metodo potenzialmente capace di risolvere un tema finora solo parzialmente soddisfatto da strumenti informatici: la gestione della conoscenza, ovvero la capacità non solo di trattare le diverse anagrafiche (di prodotto, clienti, fornitori, dipendenti,...) e di classificare i documenti tecnici o amministrativi, (analisi di mercato, specifiche tecniche, norme, procedure...) ma di arrivare anche a gestire i contenuti di questi documenti permettendo, ad es., il reperimento delle informazioni in funzione delle specifiche esigenze del richiedente, integrando quanto reso disponibile da fonti diverse[6].
Per quanto riguarda le anagrafiche, sarebbe molto semplice mappare i dati già disponibili in un RDBMS in asserzioni RDF - per ciascuna tabella:
le chiavi univoche identificano una entità;
i nomi delle colonne possono essere i predicati;
il contenuto delle colonne i valori.
Per quanto riguarda i documenti, passando per XML potrebbero essere rielaborati in modo da ricavare le necessarie asserzioni RDF, sfruttando:
la paragrafazione, normalmente standardizzata nella documentazione tecnica;
l'utilizzo di dizionari comuni (un dato elemento è chiamato allo stesso modo in documenti diversi);
Ma la ri-formulazione in modo più efficace di strutture di dati esistenti non è che il primo e più semplice dei vantaggi che il web semantico ci offre. Tramite le ontologie abbiamo la possibilità di esprimere direttamente la struttura della nostra conoscenza e permettere alle macchine di elaborare automaticamente la conoscenza stessa, non più solo le semplici informazioni. In questo modo passiamo dalla semplice informatica (elaborazione automatica di informazioni) ad una epistematica: una elaborazione automatica di conoscenza.
Prospettive per il futuro
Il web, come si presenta oggi, richiede strumenti di lavoro più progrediti, per facilitare e velocizzare la navigazione attraverso gli innumerevoli documenti dati alla pubblicazione multimediale.
Per il futuro, il web semantico si propone di dare un senso alle pagine web ed ai collegamenti ipertestuali, dando la possibilità di cercare solo ciò che è realmente richiesto.
Non sempre la Rete ci porta dove ci attenderemmo e le difficoltà d'orientamento sono significative quando siamo alla ricerca di qualche cosa e non sappiamo dove reperirlo. Scorrere una lunga quantità di elenchi alla ricerca dell'informazione desiderata è ormai quotidianità, soprattutto quando la ricerca interessa un termine piuttosto comune.
Con il Web semantico possiamo aggiungere alle nostre pagine un senso compiuto, un significato che va oltre le parole scritte, una "personalità" che può aiutare ogni motore di ricerca ad individuare ciò che stiamo cercando semplicemente perché lo è, scartando, di fatto, gli altri che non soddisfano la nostra richiesta.
Tutto questo non in virtù di sistemi di intelligenza artificiale, ma semplicemente in virtù di una marcatura dei documenti, di un linguaggio gestibile da tutte le applicazioni e dell'introduzione di vocabolari specifici, ossia insiemi di frasi alle quali possano associarsi relazioni stabilite fra elementi marcati.
Il web semantico per funzionare deve poter disporre di informazione strutturata e di regole di deduzione per gestirla, in modo da accostare quelle informazioni che un'interrogazione ha richiesto.
Tim Berners-Lee ha sottolineato che uno degli elementi fondamentali del web semantico sarà la compresenza di più ontologie. Se si vuole un sistema dinamico in grado di raffinarsi e funzionare su scala universale, bisognerà pagare il prezzo di una certa dose di incoerenza.
A partire dal 2006 il progetto di realizzazione del web semantico mediante la costruzione di ontologie è stato parzialmente revisionato. In un articolo pubblicato su International Journal on Semantic Web and Information Systems[7] dal titolo The Semantic Web Revisited[8], Tim Berners-Lee, Nigel Shadbolt e Wendy Hall hanno ridefinito alcuni aspetti del web semantico in funzione della dinamicità del World Wide Web. L'idea era quella di sviluppare e migliorare le ontologie in maniera collaborativa, grazie all'intervento di comunità di pratica. In seguito, questo nuovo approccio si è orientato sempre più a far sì che i dati vengano strutturati sotto forma di linked data anziché sotto forma di ontologie. Nell'articolo del 2009[9] emerge chiaramente che i linked data vengono considerati come le nuove colonne portanti su cui costruire il web semantico.
Agenti semantici
È da segnalare che molto lavoro è attualmente in corso per estendere le possibilità del web semantico applicando l'idea degli agenti semantici intelligenti (programmi in grado di esplorare ed interagire autonomamente con i sistemi informatici per, ad es., ricercare informazioni). Ruolo di questi agenti nel web semantico è di fornire più vaste capacità di inferenza realizzando quanto espresso in un articolo su Scientific American di Tim Berners-Lee intitolato The Semantic Web, dove si prospetta un futuro in cui Lucy fissa una visita medica alla madre utilizzando alcuni agenti capaci di "capire" la patologia, contattare i centri in grado di curarla e perfino di richiedere un appuntamento ai relativi agenti, salvo poi lasciarle la decisione di confermare[10].
Limiti
L'imprecisione del sistema è il prezzo da pagare alla sua universalità, i messaggi di "not found" (non trovato) non saranno completamente eliminati.
Tutto questo per rendere possibile l'affiancarsi di più referenze e quindi non perdere, almeno in linea programmatica, la possibilità di più definizioni, di più comprensioni di uno stesso oggetto concreto.
Un altro tema molto importante e dibattuto è come gestire la fiducia sulle asserzioni o, più esattamente, sugli autori delle asserzioni.
Per ovviare il problema delle certificazioni che sarebbero necessarie a mantenere la veridicità delle ontologie, le asserzioni vengono trasformate a loro volta in termini legati al proprio autore attraverso il ruolo (proprietà) "Asserisce" che ha per codominio il termine "Asserzione". In questo modo è possibile attribuire a questo nuovo termine un Soggetto, un Predicato e un Oggetto utilizzando le normali relazioni.
Attraverso questo procedimento, proposizioni del tipo "il bicchiere contiene del vino" vengono modificate in proposizioni del tipo "Marco ASSERISCE che il bicchiere (Soggetto) contiene (Predicato) del vino (Oggetto)". Se si vuole essere più precisi, bisognerebbe inserire nell'ontologia ben 4 asserzioni:
Japanese noodle dish Hiyamugi and edamame Hiyamugi (Japanese: 冷麦, lit. 'chilled wheat') are very thin dried Japanese noodles made of wheat.[1] They are similar to but slightly thicker than the thinnest Japanese noodle type called sōmen. The Western style noodle that most closely resembles hiyamugi is probably vermicelli.[2] They are the second thinnest type of Japanese noodle after sōmen, while the well-known udon is a thicker style of wheat noodle. Hiyamug...
Capsulitis adhesiva del hombro El hombro derecho y la articulación glenohumeral.Especialidad Traumatología, FisioterapiaSíntomas Dolor[1]Complicaciones Fractura de humero, rotura del tendón del bíceps[2]Inicio habitual 40 a 60 años[1]Tipos Primaría, secondaría[2]Causas A menudo desconocido, previo lesión en el hombro[1][2]Diagnóstico EcografíaDiagnóstico diferencial Nervio pinzado, enfermedad autoinmune, tendinopatía del bíceps, osteoart...
2009 single by ChariceAlways YouSingle by Charicefrom the album My Inspiration ReleasedMay 1, 2009 (2009-05-01)GenrePopLength4:50 (album version)LabelStar RecordsSongwriter(s)Jonathan ManaloCharice singles chronology It Can Only Get Better (2008) Always You (2009) Note to God (2009) Music videoAlways You on YouTube Always You is a pop ballad and the second single by the Filipino singer Charice Pempengco, now known as Jake Zyrus, included on his second studio album, My Inspirati...
Esta página cita fontes, mas que não cobrem todo o conteúdo. Ajude a inserir referências. Conteúdo não verificável pode ser removido.—Encontre fontes: ABW • CAPES • Google (N • L • A) (Setembro de 2023) Eliminatórias da América do Sul Copa do Mundo de 2002 Dados Participantes 10 Período 28 de março de 2000 – 14 de novembro de 2001 Gol(o)s 232 Partidas 90 Média 2,58 gol(o)s por partida Melhor marcador 9 gols: Agust...
NFL team season 2000 Green Bay Packers seasonOwnerGreen Bay Packers, Inc.PresidentBob HarlanGeneral managerRon WolfHead coachMike ShermanHome fieldLambeau FieldResultsRecord9–7Division place3rd NFC CentralPlayoff finishDid not qualifyPro BowlersFS Darren Sharper ← 1999 Packers seasons 2001 → The 2000 season was the Green Bay Packers' 80th in the National Football League (NFL) and their 82nd overall. It was the first season for which Mike Sherman was the head coach...
Наукова бібліотека НаУКМА Бібліотека ім. Тетяни та Омеляна Антоновичів 50°27′55″ пн. ш. 30°31′12″ сх. д. / 50.46539400002777853° пн. ш. 30.52025900002777803° сх. д. / 50.46539400002777853; 30.52025900002777803Координати: 50°27′55″ пн. ш. 30°31′12″ сх. д. / 50.46539400002777853° �...
Selbstporträt im Studio (1808–1810), Ungarische Nationalgalerie Signatur von Josef Abel Geburtshaus von Josef Abel in Aschach an der Donau mit Gedenktafel Josef Abel, gelegentlich Joseph Abel (* 22. August 1764[1] in Aschach an der Donau, Oberösterreich; † 4. Oktober 1818 in Wien[2]), war ein österreichischer Maler. Inhaltsverzeichnis 1 Leben 2 Werke 2.1 Porträts 3 Literatur 4 Weblinks 5 Einzelnachweise Leben Josef Abel war der Sohn des Schreinermeisters Johann Melchio...
NGC 5[1]NGC 5 oleh Sloan Digital Sky SurveyData pengamatan (J2000 epos)Rasi bintangAndromedaAsensio rekta 00j 07m 48.872dDeklinasi +35° 21′ 44.3″Pergeseran merah5111 ± 41 km/sJarak212 JtcBerdasarkan pergeseran merahMagnitudo semu (V)14,33[1]Ciri-ciriJenisEUkuran semu (V)1,2′ × 0,7′[1] NGC 5 adalah sebuah galaksi eliptis di rasi bintang Andromeda. Galaksi ini memiliki pergeseran merah generik yang diperkirakan berjarak ...
Zsuzsanna BudapestInformación personalOtros nombres Zsuzsanna Budapest, Z. BudapestNacimiento 30 de enero de 1940 (83 años)Budapest (Reino de Hungría) Nacionalidad EstadounidenseReligión Wicca DiánicaFamiliaPadres Masika SzilagyiEducaciónEducada en Universidad de VienaUniversidad de Chicago Información profesionalOcupación Autora, activista, periodista, dramaturga y autora de canciones.Conocida por Fundadora del Aquellare de Susan B. AnthonyNotas alta mater, Universidad de V...
Бокс, до 57 кгна XXXII Олімпійських іграх Місце проведенняРегоку КокугіканДати24 липня 2021 — 3 серпня 2021Учасників20 з 20 країнПризери Сена Іріє Японія Несті Петесіо Філіппіни Ірма Теста Італія Каррісс Артінгстол Велика Брита�...
Một phần của loạt bàiManga và anime Manga Lịch sử Thị trường quốc tế tiếng Việt Mangaka danh sách Dōjinshi Scanlation Nhà xuất bản Bán chạy nhất Dài nhất Phi truyền thống Gekiga Anime Lịch sử Công nghiệp ONA OVA Fansub Fandub Hãng sản xuất Dài nhất Phân loại độc giả Kodomo Shōnen Shōjo Seinen Josei Thể loại Harem Isekai Mahō shōjo Mecha Yaoi Yuri Khác Cá nhân tiêu biểu 24-nen Gumi Adachi Mitsuru Akatsuka Fujio ...
1990 American action thriller film by Deran Sarafian Not to be confused with Execution warrant. Death WarrantTheatrical release posterDirected byDeran SarafianWritten byDavid S. GoyerProduced byMark di SalleStarring Jean-Claude Van Damme Robert Guillaume Cynthia Gibb George Dickerson Patrick Kilpatrick CinematographyRussell CarpenterEdited byJohn A. BartonCheryl KrollG. Gregg McLaughlinMusic byGary ChangProductioncompany MGM-Pathé Communications[1] Distributed byMetro-Goldwyn-Mayer&#...
2020 Irish drama television series Normal PeopleGenre Psychological drama Romance Based onNormal Peopleby Sally RooneyWritten by Sally Rooney Alice Birch Mark O'Rowe Directed by Lenny Abrahamson Hettie Macdonald Starring Daisy Edgar-Jones Paul Mescal Sarah Greene ComposerStephen RennicksCountry of originIrelandOriginal languageEnglishNo. of episodes12 (list of episodes)ProductionExecutive producers Ed Guiney Andrew Lowe Emma Norton Anna Ferguson Sally Rooney Lenny Abrahamson ProducerCatherine...
Americans of Gujarati birth or descent Gujarati Americansગુજરાતી અમેરિકનોThe language spread of Gujarati in the United States according to U. S. Census 2000Total population1,330,000(2015)[1] 350,000 (2015)[1] - 434,264 (2017)[2][3] people speak the language in the USARegions with significant populationsNew Jersey, New York City, San Francisco Bay Area, Los Angeles, Washington, D.C., Chicago, Houston, Philadelphia[4]Language...
Ini adalah sebuah nama Indonesia yang tidak menggunakan nama keluarga. Nama Ali adalah sebuah patronimik. Rapsel AliAnggota Dewan Perwakilan RakyatMasa jabatan1 Oktober 2019 – 9 April 2023PenggantiIndira Chunda ThitaDaerah pemilihanSulawesi Selatan I Informasi pribadiLahir(1971-05-06)6 Mei 1971Selayar, Sulawesi Selatan, IndonesiaMeninggal9 April 2023(2023-04-09) (umur 51)Makassar, Sulawesi Selatan, IndonesiaKebangsaanIndonesiaPartai politikNasDem (2018–2023)Afiliasi politikl...
Tourism to the city Ice skating in Millennium Park is a popular visitor attraction. Tourism in Chicago draws on the city's status as a world-class destination known for its impressive architecture, first-rate museums, brilliant chefs and wide variety of neighborhood attractions.[1] In 2017, Millennium Park saw 25 million visitors, making it the top tourist destination in the Midwest and among the top ten in the United States.[2] Visitor statistics Chicago tourism recorded 55 m...
La seguridad de las armas de fuego es un conjunto de reglas y recomendaciones que permiten manipular y utilizar armas de fuego de forma de minimizar la posibilidad de accidentes.[1] De esta manera se eliminan o reducen los riesgos de daños, heridas o muertes accidentales al manipular armas. Una pistola Glock 17 asegurada para su transporte. Lineamientos y reglas sobre la seguridad de las armas de fuego Ejemplo de manipulación segura de armas de fuego. El arma es apuntada hacia el sue...
Massacre of Ryukyuan sailors in Qing-era Taiwan Not to be confused with Japanese invasion of Taiwan (1874), which is also known as the Mudan Incident (Mudanshe Shijian) in Chinese. Mudan IncidentVictims Tomb at Gokokuji Temple, Naha City. Okinawa PrefectureLocationTaiwan Prefecture, Fujian Province, Qing ChinaDateDecember 1871Attack typemassacreDeaths54[1]Victim54 Ryukyuan sailorsPerpetratorsPaiwan Formosans vte19th century conflicts involving Formosa Nerbudda incident (1842) Rover in...
Historic district in Wisconsin, United States United States historic placeBullhead Point Historical and Archeological DistrictU.S. National Register of Historic Places The vessel Empire State.LocationN. Duluth Ave., Sturgeon Bay, WisconsinCoordinates44°50′37″N 87°23′43″W / 44.84361°N 87.39528°W / 44.84361; -87.39528 (Bullhead Point Historical and Archeological District)Arealess than one acreMPSGreat Lakes Shipwreck Sites of Wisconsin MPSNRHP re...
Magnetic tape audio format introduced in 1958 This article is about the RCA 4-track cartridge. For the Muntz 4-track cartridge, see Stereo-Pak. For the 8-track cartridge, see 8-track tape. RCA Sound Tape CartridgeSize comparison of RCA tape cartridge (right) with the more common Compact CassetteMedia typeMagnetic cartridge tapeEncodingAnalogCapacity30 min per side, two sidedDeveloped byRCADimensions5 × 7.125 × 0.5 inches(137 × 197 × 13 mm)UsageHome audio recordingReleased1958Disconti...


{kind=link}


")


")


")

")
")







