This article is about the character encoding commonly mislabeled as "ANSI". For the actual ANSI character encoding, see ASCII. For the actual "ANSI extended Latin" encoding, see ANSEL.
All supported by ISO/IEC 8859-1 plus full support for French and Finnish and ligature forms for English; e.g. Danish (except for a rare exceptional letter), Irish, Italian, Norwegian, Portuguese, Spanish, Swedish, German (missing uppercase ẞ), Icelandic, Faroese, Luxembourgish, Albanian, Estonian, Swahili, Tswana, Catalan, Basque, Occitan, Rotokas, Toki Pona, Lojban, Romansh, Dutch (except the IJ/ij character, substituted by IJ/ij or ÿ), and Slovene (except the č character, substituted by ç).
Initially the same as ISO 8859-1, it began to diverge starting in Windows 2.0 by adding additional characters in the 0x80 to 0x9F (hex) range (the ISO standards reserve this range for C1 control codes). Notable additional characters include curly quotation marks and all printable characters from ISO 8859-15.
It is the most-used single-byte character encoding in the world. Although almost all websites now use the multi-byte character encoding UTF-8, as of December 2024[update] 1.1%[4] of websites declared ISO 8859-1 which is treated as Windows-1252 by all modern browsers (as demanded by the HTML5 standard[5]), plus 0.3% declared Windows-1252 directly,[4][6] for a total of 1.4%. Some countries or languages show a higher usage than the global average, in 2024 Brazil according to website use, use is at 2.9%,[7] and in Germany at 2.5%[8][9] (these are the sums of ISO-8859-1 and CP-1252 declarations).
In practice, the superset encoding Windows-1252 of ISO-8859-1 (even when standards specify the latter) is the more likely effective default[10] and it is increasingly common for UTF-8 to work whether or not a standard specifies it.
Name
It is known to Windows by the code page number 1252, and by the IANA-approved name "windows-1252".
Historically, the phrase "ANSI Code Page" was used in Windows to refer to non-DOS encodings; the intention was that most of these would be ANSI standards such as ISO-8859-1. Even though Windows-1252 was the first and by far most popular code page named so in Microsoft Windows parlance, the code page has never been an ANSI standard. Microsoft explains, "The term ANSI as used to signify Windows code pages is a historical reference, but is nowadays a misnomer that continues to persist in the Windows community."[11]
LaTeX can input Windows-1252 by using inputenc.sty with parameter ansinew (and more recently cp1252).
[12][13]
The first version of the codepage was used in Microsoft Windows 1.0. It matched the ISO-8859-1 standard (including leaving code points 0xD7 and 0xF7 undefined, as they were not in the standard at that time).
The second version of the codepage was introduced in Microsoft Windows 2.0. In this version, code points 0xD7, 0xF7, 0x91, and 0x92 are defined.
The third version of the codepage was introduced in Microsoft Windows 3.1. It defined all code points used in the final version except the euro sign and the Z with caron character pair.
The final version (shown below) was introduced in Microsoft Windows 98.
Starting in the 1990s, many Microsoft products that could produce HTML included Windows-1252-exclusive characters, but marked the encoding as ISO-8859-1, ASCII, or undeclared.[citation needed] Characters exclusive to Windows-1252 would render incorrectly on non-Windows operating systems (often as question marks).[18][19] In particular, typographers' quotes—curly variants of the standard straight apostrophes and quotation marks in US-ASCII—were commonly used in files produced in Windows applications such as Microsoft Word due to the smart quotes feature, which can automatically convert straight apostrophes and quotation marks to the curly variants.[20] To fix this, by 2000 most web browsers and e-mail clients treated the charsets ISO-8859-1 and US-ASCII as Windows-1252[citation needed]—this behavior is now required by the HTML5 specification.[5] Undeclared charsets in HTML are also assumed to be Windows-1252.[21][22]
Although Windows NT supported Unicode and attempted to encourage programs to use it, it only provided the 16-bit code units of UCS-2/UTF-16, despite the existing support for other multibyte character encodings. As many applications preferred to use 8-bit strings, Windows-1252 remained the most popular encoding on Windows even after it added support for UTF-16. Unicode support in Windows has improved over time, with UTF-8 support available starting in Windows 10.
Codepage layout
The following table shows Windows-1252. Differences from ISO-8859-1 have the Unicodecode point number below the character, based on the Unicode.org mapping of Windows-1252 with "best fit". A tooltip, generally available only when one points to the immediate right of the character, shows the Unicode code point name and the decimal Alt code.
According to the information on Microsoft's and the Unicode Consortium's websites, positions 81, 8D, 8F, 90, and 9D are unused; however, the Windows API MultiByteToWideChar maps these to the corresponding C1 control codes. The "best fit" mapping documents this behavior, too.[23]
Related encodings
OS/2 extensions
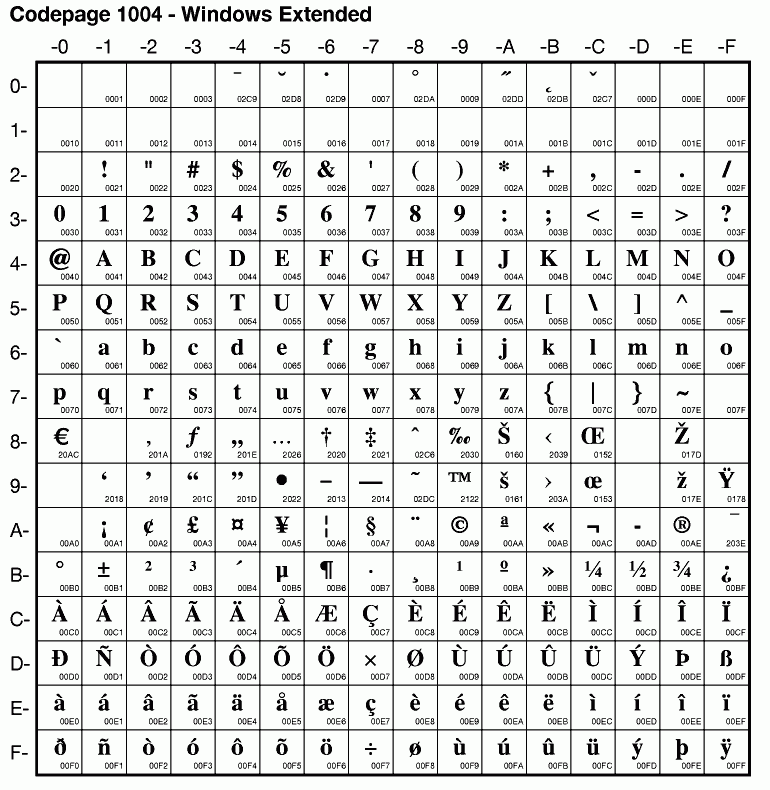
The OS/2 operating system supports an encoding by the name of Code page 1004 (CCSID 1004) or "Windows Extended".[28][29] This mostly matches code page 1252, with the exception of certain C0 control characters being replaced by diacritic characters.
There is a rarely used, but useful, graphics extended code page 1252 where codes 0x00 to 0x1f allow for box drawing as used in applications such as MSDOS Edit and Codeview. One of the applications to use this code page was an Intel Corporation Install/Recovery disk image utility from mid/late 1995. These programs were written for its P6 User Test Program machines (US example[34]). It was used exclusively in its then EMEA region (Europe, Middle East & Africa). In time the programs were changed to use code page 850.
Each Palm OS device supports a single language and a single character encoding, depending on its locale.[35]
For languages such as English and French, Palm OS uses a custom character encoding based on Windows-1252. For Japanese, it instead uses a multibyte character encoding based on code page 932. Regardless of the system locale, all characters in the range 0x00 to 0x7F are guaranteed to be the same, except 0x5D which is the Yen sign in Japanese and a backslash on all others.[35]
Palm OS 3.1 introduced several changes to the character encoding to better align with Windows-1252:[36]
The special Palm OS glyphs "shortcut stroke" (0x9D) and "command stroke" (0x9E) were copied to 0x16 and 0x17, to ensure they were in the range guaranteed to be consistent between locales.[36] Starting in Palm OS 3.3, 0x16 and 0x17 are the only code points for those characters,[37] leaving 0x9D and 0x9E undefined.[38]
The numeric space (0x80) and horizontal ellipsis (0x85) were copied to 0x19 and 0x18 (respectively), to ensure they were in the range guaranteed to be consistent between locales.[36][37]
The Euro sign was added at 0x80, replacing what was previously the numeric space.[37]
The playing card suits were copied to the font Symbol 9,[36] although their original code points remain valid.[37][38]
The following is the variant of Windows-1252 used by Palm OS 3.3 onward for English and several other locales.[37]Python gives it the palmos label, describing it as the encoding for Palm OS 3.5.[39][40] Differences from Windows-1252 have their Unicode code point.
^Prior to Palm OS 3.1, the character at code point 0x80 was U+2007 NUMERIC SPACE; starting in Palm OS 3.1, 0x80 is the Euro sign and 0x19 is U+2007 NUMERIC SPACE instead.[37]
^Starting in Palm OS 3.1, this character is also duplicated at 0x18.[36][37]
^Prior to Palm OS 3.3, this code point was the Palm OS-exclusive character "shortcut stroke"; starting in Palm OS 3.3, this code point is undefined.[36][37]
^Prior to Palm OS 3.3, this code point was the Palm OS-exclusive character "command stroke"; starting in Palm OS 3.3, this code point is undefined.[36][37]
^van Emden, Eva (28 January 2011). "How to make typographers' quotes in HTML". vancouvereditor.com. Retrieved 7 January 2024. If you use typographers' quotes without specifying the right character encoding for your HTML file, some of your viewers are going to see question marks, boxes, or other crazy symbols instead of the beautiful curly quotes you intended them to see.
^"NetWare Web Search: Understanding Character Set Encodings". Novell Documentation. Novell. if a document does not contain a CHARSET encoding value, the default encoding for HTML documents is ISO-8859-1, also known as Latin1. The default encoding for plain text documents is US-ASCII.
^Observed behavior in Chrome, this may be UTF-8 in some browsers.[original research?]
^Borgendale, Ken (2001). "Codepage 1004 - Windows Extended". OS/2 codepages by number. Archived from the original on 2018-05-13. Retrieved 2018-05-13. (version based on current version of Windows-1252)

{kind=link}
{kind=link}
