RAID er en forkortelse for Redundant Array of Inexpensive Disks (redundant matrise av billige disker), også kalt Redundant Array of Independent Disks (redundant matrise av uavhengige disker) og er en metode for datalagring. Teknologien bygger på at man bruker en serie av enkeltstående harddisker som et samordnet datalager.[1]
RAID er et samlebegrep for datalagringssystemer som på ulikt vis fordeler og dupliserer data ut over flere fysiske harddisker. Forskjellige konfigurasjoner refereres som ulike RAID-nivå (RAID 0, RAID 1 osv.). Målet med RAID-teknologi er å oppnå større ytelse og økt sikkerhet.[1]
I praksis kombinerer RAID-teknologi flere disker til en enkelt logisk enhet. For operativsystemet, og dermed brukeren, opptrer RAID-serien som én enkelt harddisk på datamaskinen, mens det i virkeligheten er en rekke av harddisker styrt av en RAID-kontroller. Denne kontrollen kan skje i maskinvaren, eller den kan være programvare-basert.
Prinsipper
Striping er en teknikk for å øke lese- og skrivehastigheten til og fra disk. Dette innebærer at data splittes opp og skrives fordelt over flere disker. Man kan da lese inn disse dataene mye hurtigere, siden man kan bruke overføringskapasiteten fra alle diskene samtidig. RAID 0 er en ren striping.[1][2]
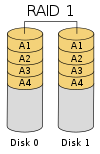
Speiling vil si at samme data skrives på flere steder samtidig, vanligvis på to disker. Disse diskene er da eksakte kopier av hverandre. Dette gir også bedre ytelse og sjansen for å miste data på grunn av diskkrasj reduseres vesentlig. Hvis en disk får en feil kan man bare sett inn en ny og kopiere over dataene fra den bevarte disken. RAID 1 er et rent speilet system.[1][2]
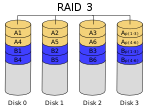
Paritetsbit er en bit som beregnes ut fra et sett av andre bits. Hvis man for eksempel har de binære verdiene A1=0011, A2=0101 og A3=0000 kan man generere modulo-2-summen Ap=0110 (Ap = A1 XOR A2 XOR A3). Modulo-2-sum er 1 hvis et odde antall blokker har 1 og 0 hvis et like antall blokker har 1. Dette bygger på det matematiske prinsippet eksklusiv disjunksjon. Hvis en av verdiene går tapt i en diskkrasj kan man rekonstruere den ut fra de andre diskene. Man kan da sikre seg mot et diskkrasj uten å doble alle data. RAID 3 er enkleste variant av dette prinsippet.[2]
RAID-nivåer
| Nivå |
Beskrivelse |
Minste antall disker |
Plasseffektivitet |
Feiltoleranse |
Illustrasjon
|
| RAID 0
|
Stripet sett[1] uten speiling eller paritet
|
2
|
1
|
0 (Ingen)
|

|
| RAID 1
|
Speilet sett[1] uten striping eller paritet
|
2
|
1/n
|
n-1 disker
|
|
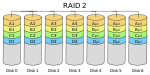
| RAID 2
|
Hammingkode-parietet (ECC)
Det er ikke utviklet kommersielle implementasjoner av RAID 2.[2]
|
3
|
1 − 1/n ⋅ log2(n-1)
|
1 disk
|
|
| RAID 3
|
Sett med egen parietetsdisk basert på byte-nivå.[1]
|
3
|
1 − 1/n
|
1 disk
|
|
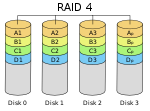
| RAID 4
|
Sett med egen paritetsdisk basert på sektor-nivå.[1]
|
3
|
1 − 1/n
|
1 disk
|
|
| RAID 5
|
Ligner på RAID 4, men parietetsbitene er spredt over alle diskene (distribuert). Dette er en fordel, fordi det ellers kan bli en flaskehals å holde parietetsdisken oppdatert, i RAID 3 og 4 må det skrives til parietetsdisken i alle operasjoner.[1]
|
3
|
1 − 1/n
|
1 disk
|

|
| RAID 6
|
Dobbel distribuert parietet. Det finnes ulike varianter av RAID 6, men de har felles at de kan redde data også ved flere samtidige diskkrasj. Dette er særlig viktig med store disker fordi det tar mye lengre tid å gjenopprette en stor disk.[2]
|
4
|
1 − 2/n
|
2 disker
|

|
RAID 0
RAID 0 (også kjent som et stripet sett) deler data jevnt over to eller flere disker uten paritetsinformasjon for redundans. Dette var ikke et av de originale RAID-nivåene, og er altså ikke redundant. Hensikten er å øke ytelsen, men det kan også være en måte å skape større logiske disker ut av flere mindre fysiske.
Et RAID 0 kan lages av disker av forskjellig størrelse, men bidraget fra hver enkelt disk er begrenset til størrelsen på den minste disken. For eksempel: Hvis en 600 GB disk stripes sammen med en 500 GB disk så er størrelsen på settet 1000 GB (500 GB + 500 GB, eller det dobbelte av den minste disken).
Ideell oppførsel for et RAID 0 vil være hvor I/O-operasjonene (altså lesing og skriving) deles opp i blokker av lik størrelse og spres jevnt utover begge diskene. RAID 0 med flere disker er mulig, men påliteligheten til settet er lik gjennomsnittlig pålitelighet til diskene delt på antall disker i settet. Dette vil si at påliteligheten er omtrent omvendt proporsjonal med antall disker – et sett med to disker er altså halvparten så pålitelig som en enkelt disk. Grunnen til dette er at filsystemet er spredt over alle diskene. Hvis én disk feiler, så er dataene i hele settet i utgangspunktet tapt. Deler av dataene kan tenkelig hentes ut med spesialverktøy.
Blokkstørrelsen kan i teorien være så liten som en byte, men er nesten alltid en multippel av harddiskens sektorstørrelse på 512 bytes. Dette lar hver disk søke uavhengig når data skrives eller leses i en vilkårlig rekkefølge. Hvis sektoren er spredt jevnt utover så vil den oppfattede søketiden være noe mellom den raskest og seneste søketiden for alle diskene i settet. Dette er fordi alle diskene må lese sin del av dataene før I/O-operasjonene kan fullføres. Søketiden ligger vanligvis på litt mer enn det én enkelt disk ville ligge på, da rotasjonen til diskene er synkronisert. Overføringshastigheten til settet vil være den samlede overføringshastigheten til alle diskene, bare begrenset av RAID-kontrolleren.
RAID 6
RAID 6 er ulike metoder for å bevare alle data ved flere samtidige diskkrasj. En variant av dette er hammingkodet RAID 6 som tåler to samtidige diskkrasj. I denne konfigurasjonen nummererer man diskene og alle toerpotenser blir parietetsdisker (Disk 1, 2, 4, 8 osv.). Maksimalt antall disker totalt blir 2k - 1, der k er antall parietetsdisker.[2]
Nøstede RAID-nivåer
Man opererer også med nøstede RAID-nivåer, som er kombinasjoner av de nevnte nivåene. F.eks. er det vanlig at man striper data i tillegg til å spre parietetsdataene. Dette kan da betegnes RAID 5+0.
I RAID 10 (også kjent som RAID 1+0) har alle diskene en speiling og i tillegg er dataene stripet ut over parene (RAID 1 kombinert med RAID 0). Dette er i ferd med å bli et vanlig oppsett i store datasenter. Årsaken til at man kan tillate seg så stor redundans er at harddisker har blitt så store og billige at kostnaden er liten i forhold til fordelene ved å ha et enkelt og robust oppsett.[2]
Se også
Aritmetisk logisk enhet
Referanser
Eksterne lenker






