Algoritmos de estimação de distribuição (AED) são métodos evolutivos que utilizam técnicas de estimação de distribuição ao invés de operadores genéticos [1].
Fluxograma de um algoritmo de estimação de distribuição.
AED's são consequência dos algoritmos genéticos, sendo motivados pela deficiência destes, principalmente pela sua incapacidade de representar e manipular as dependências entre as variáveis. Este problema é conhecido como linkage problem.
Em seu trabalho seminal sobre algoritmos genéticos, Holland [2] já havia reconhecido que, se a interação das variáveis fosse utilizada, certamente traria benefícios aos algoritmos genéticos. Esta fonte de informação, até então inexplorada, foi chamada de informação de ligação (linkage information).
Assim, para contornar estes obstáculos dos algoritmos genéticos, os AEDs representam explicitamente as dependências entre as variáveis através de modelos probabilísticos, como desde simples representação em vetores de probabilidades até modelos mais complexos, como rede bayesiana, estruturas em árvore (grafo), cadeias de Markov, entre outras. Os AEDs utilizam estes modelos probabilísticos como guias para desempenhar a busca em um determinado espaço de soluções.
Considere o seguinte exemplo de um AED. Seja uma população representada por vetores binários de comprimento 4. O AED pode empregar um único vetor composto por 4 probabilidades () onde cada é a probabilidade da posição receber o valor 1. Usando este vetor de probabilidades é possível criar qualquer quantidade de soluções candidatas. Ao fim de cada geração, este vetor de probabilidades vai sendo atualizado segundo os melhores indivíduos da geração corrente.
Definição
Diferentemente dos algoritmos genéticos comuns, que utilizam operadores de recombinação e mutação para gerar novos indivíduos da população, os algoritmos de estimação de distribuição fazem uso de informações extraídas do conjunto de soluções promissoras presentes na população daquela geração. Uma maneira de utilizar a informação global sobre um conjunto de soluções promissoras é estimar sua distribuição e usar esta estimativa para gerar novos indivíduos.
Os algoritmos que fazem uso deste princípio são chamados de Algoritmos de Estimação de Distribuição - AED (do inglês Estimation of
distribution algorithm) [3]. Essas distribuições contemplam diretamente
as interações das variáveis que compõem o espaço de busca.
Formalmente, pode-se definir um AED como uma quádrupla da forma [1]:
onde,
: método para codificação dos indivíduos;
: população de n indivíduos codificados;
: operador estocástico (ou determinístico) para seleção;
: Estimador da distribuição das melhores soluções (na iteração corrente).
Nota-se a eliminação dos componentes de recombinação, de mutação e suas probabilidades, em relação ao algoritmo genético (AG).
No entanto, a tarefa de estimação deverá ser feita levando em conta a complexidade do modelo utilizado, como será visto nas seções seguintes. Dependendo do modelo de estimação utilizado, alguns parâmetros adicionais deverão ser informados.
Diferentemente do AG, em que as inter-relações (blocos construtivos) das variáveis representando os indivíduos são mantidas
implicitamente, nos AEDs essas relações são expressadas explicitamente através da distribuição de probabilidade conjunta associada
aos indivíduos selecionados em cada iteração.
A sequência estrutural do AED é bastante similar ao AG, diferindo na maneira como são gerados novos indivíduos.
A seleção das soluções promissoras pode ser realizada de forma determinística ou estocástica, privilegiando indivíduos
com melhores valores de fitness. A população pode ser amostrada integralmente a partir da distribuição de probabilidade; ou,
visando maior exploração do ambiente, estipular uma porcentagem para adição de novos indivíduos
gerados aleatoriamente; ou ainda substituindo alguns indivíduos da população anterior pelos novos
indivíduos amostrados pela distribuição.
Gera população inicial aleatoriamente
enquanto condição de parada não for satisfeita faça
Avalição:
Seleção:
Estimação da distribuição de probabilidades, , do conjunto selecionado
Amostre a nova população a partir de retorne o melhor indivíduo encontrado.
Exemplos de critérios de parada são: um número fixo de iterações, um número fixo de diferentes
avaliações de fitness dos indivíduos e ausência de melhorias do melhor indivíduo em um
certo número de iterações subsequentes.
O passo fundamental nesta classe de algoritmos é como estimar a distribuição das soluções promissoras.
Na realidade, a estimação da distribuição de probabilidade conjunta associada às variáveis,
a partir de soluções promissoras selecionadas, constitui o gargalo destes algoritmos.
Será necessário então um balanço entre a precisão desta estimação e seu custo computacional.
Tipos de AEDs
Os algoritmos presentes nesta classe diferenciam-se basicamente pela forma como a estimação é realizada, sendo classificados
de acordo com a complexidade do modelo probabilístico utilizado: variáveis sem dependência; dependência aos pares; dependência
multivariada e modelos de mistura[4].
A seguir, serão apresentadas algumas abordagens de AEDs, tanto para problemas de otimização em espaços
discretos, quanto em espaços contínuos. Esta revisão será organizada considerando os quatro níveis
de complexidade do modelo probabilístico, citados acima e utilizados para extrair as interdependências
das variáveis que formam o espaço de busca.
Modelos sem dependências
A maneira mais simples de estimativa é supor que as variáveis do problema são independentes, ou seja, não há
qualquer tipo de relação entre elas (veja figura ao lado). Formalmente, a distribuição
de probabilidade conjunta é fatorizada como o produto de n distribuições de probabilidades independentes e univariadas:
onde x é o conjunto de soluções promissoras, em um espaço de busca n-dimensional,
selecionadas para a estimação.
O modelo de estimação utilizado para gerar novos indivíduos contém o conjunto de frequências de
valores das variáveis que representam a solução no conjunto selecionado. Assim, estas frequências
são usadas para guiar a busca, gerando novos indivíduos, variável por variável de acordo com
os valores de frequência. Dessa forma, os blocos construtivos de primeira ordem são reproduzidos
e mesclados eficientemente [5]. Algoritmos baseados neste mecanismo são indicados
para problemas em que as variáveis não possuem interação mútua [6][3].
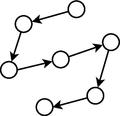
AED sem dependência. Os nós representam as variáveis do problema e a ausência de arestas entre os nós indica que não há dependência entre as variáveis.
Exemplos de algoritmos que fazem uso deste modelo probabilístico, no espaço de variáveis discretas,
são: o UMDA ( Univariate Marginal Distribution Algorithm) [3], onde cada
distribuição marginal univariada é estimada pelas respectivas frequências marginais; o PBIL
(Population Based Incremental Learning) [7], que utiliza a regra de aprendizado
hebbiano para a atualização do vetor de probabilidades, a partir do conjunto de soluções selecionadas;
e o CGA (Compact Genetic Algorithm) [8], que atualiza o vetor de probabilidades p(x) a partir de
uma competição entre dois indivíduos amostrados com base em p(x), sendo p(x) deslocado em direção ao indivíduo vencedor.
Para o caso contínuo, supõe-se que a função densidade de probabilidade conjunta segue uma distribuição normaln-dimensional,
que é fatorizada pelo produto de n densidades normais unidimensionais e independentes [4]. O problema
então consiste na estimação dos parâmetros da distribuição. Formalmente, para o caso de uma distribuição normal, a função densidade de probabilidades é descrita por:
onde denota a média da i-ésima variável e sua variância.
O algoritmo UMDA foi estendido ao espaço de variáveis contínuas (UMDA) [9]. Aqui, a cada iteração o algoritmo busca por uma função densidade que melhor se ajuste à variável,
obtendo seus parâmetros pela estimativa da máxima verossimilhança. Já o algoritmo SHCLVND
(Stochastic Hill Climbing with Learning by Vectors of Normal Distributions) [10]
atualiza os parâmetros da distribuição normal, média e variância, pela regra de Hebb para a média
e uma política de redução para a variância.
Modelos com dependência aos pares
Embora a suposição de independência entre as variáveis seja satisfeita para alguns problemas, nem sempre esta hipótese
é verificada, sendo então necessário levar em consideração algumas dependências. Quando a dependência
aos pares é considerada, estabelece-se um compromisso entre a precisão e o custo computacional.
A distribuição de probabilidades conjunta é fatorizada como:
onde é a variável da qual é dependente.
Enquanto os algoritmos que consideram variáveis independentes estimam apenas os parâmetros
do modelo, na dependência aos pares a aprendizagem paramétrica é estendida para a aprendizagem
da estrutura do modelo de dependência (um grafo direcionado).
No contexto discreto, o MIMIC (Mutual Information Maximizing Input Clustering)
[11] usa uma cadeia simples de distribuição (veja figura a seguir)
que maximiza a informação mútua das variáveis vizinhas (posições na cadeia), através de uma
abordagem gulosa, que, embora eficiente, não garante a otimalidade global. A utilização
de árvores de dependência foi formalizada por [12][13] no COMIT (Combining Optimizers with Mutual Information Trees), que utiliza uma rede bayesiana
com estrutura em árvore que é construída pelo algoritmo proposto por [14].
O algoritmo BMDA (Bivariate Marginal Distribution Algorithm) [15]
implementa uma floresta (um conjunto de árvores de dependência mutuamente independentes)
como modelo probabilístico. Uma floresta pode ser interpretada como uma generalização do conceito
de árvores de dependência. O algoritmo usa o teste Chi-quadrado de Pearson para determinar
quais variáveis serão conectadas.
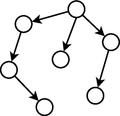
Modelo probabilístico com dependência aos pares. Algoritmo MIMIC.
Algoritmo COMIT.
Algoritmo BMDA.
No caso contínuo, o MIMIC foi estendido para problemas com variáveis contínuas, supondo que o
modelo de probabilidades é uma distribuição normal bivariada que utiliza um resultado de
[16] para calcular e usar a entropia como medida para determinar dependência
entre duas variáveis.
Algoritmos desta família reproduzem e mesclam blocos construtivos de segunda ordem eficientemente,
obtendo sucesso na aplicação junto a problemas lineares e quadráticos [3][11].
Modelos com múltiplas dependências
Apesar de modelos que consideram dependência aos pares serem eficientes em certos cenários,
em problemas multivariados ou com alta sobreposição de blocos construtivos, este tipo de modelo
se mostra insuficiente para representar o espaço das boas soluções. Esta classe de problemas
requer estimativas mais completas, mesmo à custa de uma maior demanda computacional.
No algoritmo ECGA (Extended Compact Genetic Algorithm) [17], no domínio discreto, as variáveis são divididas em grupos, cujas variáveis de um mesmo grupo (bloco construtivo)
são independentes entre si, como mostra a figura abaixo. A divisão dos grupos é feita por um procedimento guloso que utiliza a métrica Minimum description length (MDL) [18]. A distribuição de probabilidades conjunta foi codificada por uma rede bayesiana
no algoritmo EBNA (Estimation of Bayesian Networks Algorithm) [19].
Neste método, a estrutura da rede é construída por uma estratégia gulosa de busca local utilizando
alguma métrica para medir a qualidade da rede, como BIC (Bayesian Information Criterion),
K2 com penalidades (K2+pen) ou teste de (in)dependência condicional.
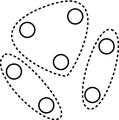
Modelos gráficos com múltiplas dependências. Algoritmo ECGA.
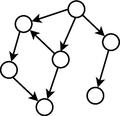
Modelos gráficos dos algoritmos EBNA e BOA.
A métrica de pontuação Bayesian-Dirichlet (BD) foi utilizada no algoritmo BOA
(Bayesian Optimization Algorithm) [20], que, de forma incremental, vai adicionando novas arestas no grafo até que não haja melhorias na qualidade do modelo.
Com o objetivo de reduzir a cardinalidade do espaço de busca, os autores propuseram restringir,
a um número fixo, a quantidade de pais para cada nó da rede bayesiana.
No contexto de variáveis contínuas, o EMNA (Estimation Multivariate Normal Algorithm)
[21] é baseado na estimação de uma função densidade normal multivariada em
cada geração. Apesar do grande número de parâmetros a serem estimados, os cálculos envolvidos são
simples.
Os algoritmos desta classe se distinguem das outras abordagens pela capacidade de representar
as interações multivariadas presentes no problema. Apesar destes algoritmos demandarem alto custo
computacional, devido ao aprendizado de modelos mais complexos, o número de avaliações de fitness
tende a ser reduzido significativamente [20]. Por isso,
a complexidade computacional total tende a ser reduzida para problemas mais complexos, em que
o cálculo da função-objetivo é computacionalmente oneroso.
Modelos de mistura
No caso de problemas multimodais, outros modelos probabilísticos mais flexíveis podem ser empregados.
Modelos de mistura fazem uso do procedimento de agrupamento das soluções promissoras e posicionam
distribuições de probabilidade junto a cada agrupamento. O modelo pode ser descrito como segue:
onde representa o peso do i-ésimo componente da mistura e é a
distribuição de probabilidade do i-ésimo grupo criado pelo método de agrupamento de dados. O peso
de cada componente juntamente com os parâmetros das distribuições de probabilidades são obtidos
por algum procedimento dedicado, como o algoritmo EM (Expectation-Maximization)
[22].
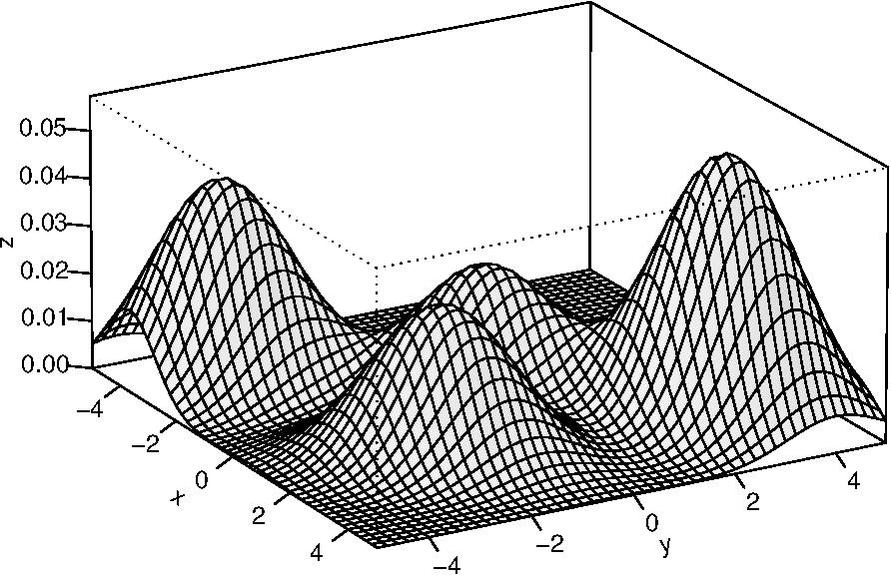
A figura a seguir apresenta um modelo de mistura gaussiano arbitrário composto de quatro componentes.
Um dos principais obstáculos desses métodos é a necessidade de conhecer, de antemão, o número de
componentes, onde cada grupo busca representar um pico da função a ser otimizada. De fato,
o número de componentes do modelo dependerá de quão multimodal o problema é. No entanto, existem
formas de estimar este parâmetro, como por exemplo, através dos critérios de informação:
Bayesian Information Criterion, Akayke Information Criterion, entre outros.
No caso discreto, é possível criar um modelo de mistura em que cada componente é uma rede bayesiana, como
o EMDA (Estimation of Mixtures of Distributions Algorithm) descrito por [23], embora
este tipo de estimador seja mais aplicado para o caso contínuo.
Para o espaço de variáveis contínuas, [24] propuseram o algoritmo AMix
(Adaptative Gaussian Mixture'), que utiliza um modelo de mistura adaptativo.
O número de componentes do modelo de mistura pode variar durante
a execução do algoritmo. O algoritmo EDA[25][26]
emprega um modelo de mistura gaussiano que utiliza uma forma de treinamento ao longo do tempo, o que reduz significativamente
o custo computacional do algoritmo. Além disso, auto-ajusta a número de componentes de mistura
no decorrer do processo de busca.
Aplicações
Os AEDs vem sendo aplicados em uma gama de problemas de diversas áreas de conhecimento. Dentre as aplicações podemos destacar:
seleção de atributos, evolução de pesos de redes neurais MLP, geração de regras SE-ENTÃO para sistemas nebulosos, expressão gênica, análise de estrutura de proteínas, em problemas de otimização multiobjetivo e de otimização dinâmica.
Referências
↑ abA.R. Gonçalves. Otimização em ambientes dinâmicos com variáveis contínuas empregando algoritmos de estimação de distribuição. Dissertação de mestrado. Faculdade de Engenharia Elétrica e de Computação. Universidade Estadual de Campinas (Unicamp). 2011.
↑J.H. Holland. Adaptation in natural and artificial systems. University of Michigan Press, Ann Harbor,1975.
↑ abcdH. Mühlenbein & G. Paaß. From recombination of genes to the estimation of distributions I. Binary parameters. Parallel Problem Solving from Nature-PPSN IV, pages 178–187, 1996.
↑ abP. Larrañaga, J.A. Lozano & E. Bengoetxea. Estimation of distribution algorithms based on multivariate normal and Gaussian networks. Technical Report KZZA-IK-1-01, Department of Computer Science and Artificial Intelligence, University of the Basque Country, 2001.
↑M. Pelikan, D.E. Goldberg & F.G. Lobo. A survey of optimization by building and using probabilistic models. Computational optimization and applications, 21(1):5–20, 2002.
↑G. Harik, E. Cantú-Paz, D.E. Goldberg & B.L. Miller. The Gambler’s Ruin Problem, Genetic Algorithms, and the Sizing of Populations. In Proceedings of the IEEE Conference on Evolutionary Computation, pages 7–12, 1997.
↑
S. Baluja. Population-based incremental learning: A method for integrating genetic search based
function optimization and competitive learning. Technical Report CMU-CS-94-163, Carnegie Mellon University, Pittsburgh, PA, 1994.
↑G.R. Harik, F.G. Lobo & D.E. Goldberg. The compact genetic algorithm. In Proceedings of the IEEE Conference of Evolutionary Computation, pages 523–528, 1998.
↑
P. Larrañaga, R. Etxeberria, J.A. Lozano & J.M. Pena. Optimization by learning and simulation of
Bayesian and Gaussian networks. Technical Report EHU-KZAAIK-4, University of the Basque Country, 1999.
↑
S. Rudlof & M. Köppen. Stochastic hill climbing with learning by vectors of normal distributions. In
Proceedings of the American Association for Artificial Intelligence, Nagoya, Japan, 1996.
↑ abJ.S. De Bonet, C.L. Isbell & P. Viola. MIMIC: Finding optima by estimating probability densities.
In Advances in Neural Information Processing Systems, volume 4, pages 424–430. The MIT Press,
1997.
↑S. Baluja & S. Davies. Using optimal dependency-trees for combinatorial optimization: Learning the structure of the search space. In Proceedings of 14th International Conference on Machine Learning, pages 30–38. Morgan Kaufmann, 1997.
↑S. Baluja & S. Davies. Fast Probabilistic Modeling for Combinatorial Optimization. In Proceedings of the American Association for Artificial Intelligence, pages 469–476, 1998.
↑C. Chow & C. Liu. Approximating discrete probability distributions with dependence trees. IEEE transactions on Information Theory, 14(3):462–467, 1968.
↑M. Pelikan & H. Mühlenbein. The bivariate marginal distribution algorithm. Advances in Soft Computing-Engineering Design and Manufacturing, pages 521–535, 1999.
↑G. Harik. Linkage learning via probabilistic modeling in the ECGA. Technical Report IlliGAL 99010, University of Illinois at Urbana-Champaign, 1999.
↑J. Rissanen. Modeling by shortest data description. Automatica, 14(5):465–471, 1978.
↑R. Etxeberria & P. Larrañaga. Global optimization using Bayesian networks. In Second Symposium on Artificial Intelligence (CIMAF-99), pages 332–339, 1999.
↑ abM. Pelikan, D.E. Goldberg & E. Cantú-Paz. Bayesian optimization algorithm, population sizing, and time to convergence. In Proceedings of the Genetic and Evolutionary Computation Conference GECCO’00, pages 275–282, 2000.
↑P. Larrañaga, J.A. Lozano & E. Bengoetxea. Estimation of distribution algorithms based on multivariate normal and Gaussian networks. Technical Report KZZA-IK-1-01, Department of Computer Science and Artificial Intelligence, University of the Basque Country, 2001.
↑A.P. Dempster, N.M. Laird & D.B. Rubin. Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 39(1):1–38, 1977.
↑
J.M. Pena, J.A. Lozano & P. Larrañaga. Benefits of data clustering in multimodal function
optimization via EDAs. In P. Larrañaga, J.A. Lozano, editor, Estimation of Distribution Algorithms: A new tool for Evolutionary Computation. Kluwer Academic Publishers, 2001.
↑
M. Gallagher, M. Frean & T. Downs. Real-valued evolutionary optimization using a flexible
probability density estimator. In Proceedings of the Genetic and Evolutionary Computation Conference GECCO’99, pages 840–846, 1999.
↑
A.R Gonçalves & F.J. Von Zuben. Hybrid evolutionary algorithm guided by a fast adaptive Gaussian
mixture model applied to dynamic optimization problems. In: Proceedings of III Workshop on Computational Intelligence (WCI’2010)- Joint Conference, São Bernardo do Campo, São Paulo, pag. 553–558, ISBN 978-8-5766-9250-8, Outubro 2010.
↑André R Gonçalves, Fernando J Von Zuben. Online learning in estimation of distribution algorithms for dynamic environments. In: 2011 IEEE Congress on Evolutionary Computation (CEC), 2011, New Orleans. 2011 IEEE Congress of Evolutionary Computation (CEC). p. 1-6.
Henrik II av Guise, oljemålning av Anthonis van Dyck, 1634. Henrik II av Guise, född 4 april 1614, död 2 juni 1664, var en fransk hertig och tronpretendent. Som yngre son till Charles av Guise anvisades Henrik det andliga ståndet, och utnämndes redan som barn till kardinal. I samband med faderns död övertog han trots detta hertigdömet Guise. Han deltog i konspirationer mot kardinal Armand-Jean du Plessis Richelieu och måste dödsdömd hålla sig i landsflykt till 1644. Under Masaniel...
National park in Minnesota, United States Voyageurs National ParkIUCN category II (national park)Early autumn in Voyageurs National ParkLocation in MinnesotaShow map of MinnesotaLocation in the United StatesShow map of the United StatesLocationSaint Louis & Koochiching counties, Minnesota, United StatesNearest cityInternational FallsCoordinates48°30′N 92°53′W / 48.500°N 92.883°W / 48.500; -92.883Area218,200 acres (883 km2)[1]EstablishedApr...
Pantai Nguborlat Pesisir Pantai Nguborlat Informasi Lokasi Pantai Ngurbloat, Ngilngof, Manyeuw, Maluku Tenggara Negara Indonesia Jenis objek wisata Wisata pantai Gaya Alami Fasilitas • Pasir Putih Seperti Tepung • Sunset • Spot Foto • Air Laut Landai dan Ombak yang Tenang • Penginapan Bergaya Tropis Sekelas Internasional Pantai Ngurbloat terletak di Desa Ngilngof di Kepulauan Kei, Kabupaten Maluku Tenggara, Provinsi Maluku merupakan salah satu desa wi...
Este artículo o sección tiene referencias, pero necesita más para complementar su verificabilidad.Puedes avisar al redactor principal pegando lo siguiente en su página de discusión: {{sust:Aviso referencias|Cameltoe}} ~~~~Este aviso fue puesto el 11 de agosto de 2023. Un cameltoe. Cameltoe (en español, literalmente: pezuña de camello) es un término de jerga inglesa que define la línea que permite apreciar los labios mayores de la vulva de la mujer bajo la ropa muy estrecha o ajustada...
1996 studio album by The Brian Jonestown MassacreThank God for Mental IllnessStudio album by The Brian Jonestown MassacreReleasedOctober 25, 1996RecordedJuly 11, 1996StudioOur House (San Francisco)Genre Psychedelic folk country rock country blues[1] lo-fi folk rock Length63:35LabelBomp!ProducerAnton NewcombeThe Brian Jonestown Massacre chronology Their Satanic Majesties' Second Request(1996) Thank God for Mental Illness(1996) Give It Back!(1997) Thank God for Mental Illness is...
Capitulaire De Villis Capitulare de villis vel curtis imperii LXX Droit Romano-germain Données clés Type de document Capitulaire Législateur Charlemagne Année fin VIIIe début IXe siècle Langue Latin Droit du haut Moyen Âge modifier - modifier wikidata Si ce bandeau n'est plus pertinent, retirez-le. Cliquez ici pour en savoir plus. Certaines informations figurant dans cet article ou cette section devraient être mieux reliées aux sources mentionnées dans les sections « ...
Untuk surat kabar Malaysia, lihat Guang Ming Daily (Malaysia). Guangming Daily光明日报Laman depan edisi pertama pada 16 Juni 1949TipeSurat kabar harianFormatLembar lebarDidirikan16 Juni 1949Pandangan politikPartai Komunis TiongkokBahasaTionghoaPusatBeijingSirkulasi surat kabar490.000Situs webwww.gmw.cn Guangming Daily Hanzi sederhana: 光明日报 Hanzi tradisional: 光明日報 Alih aksara Mandarin - Hanyu Pinyin: Guāngmíng Rìbào - Wade-Giles: Kuang-ming Jih-pao Markas besar Guangmin...
Indian stock market investor This article contains content that is written like an advertisement. Please help improve it by removing promotional content and inappropriate external links, and by adding encyclopedic content written from a neutral point of view. (April 2022) (Learn how and when to remove this template message) This biographical article is written like a résumé. Please help improve it by revising it to be neutral and encyclopedic. (November 2020) Vijay KediaBornCalcutta, IndiaE...
SDN Pondok Kelapa 11 PetangInformasiJenisSekolah Dasar NegeriNomor Statistik Sekolah101016403168Kepala SekolahEko Lestariyanti, M.Pd [1]Jumlah kelasKelas I sampai kelas VIJumlah siswa231 orang[1]AlamatLokasiKomplek Perumkar Pemda DKI Pondok KelapaKecamatan Duren SawitJakarta Timur, Jakarta Timur, Jakarta, IndonesiaTel./Faks.+62-21-8652-341Koordinat6°14′24″S 106°56′21″E / 6.24011666667°S 106.93908333°E / -6.24011666667; 106.939...
Опис Обкладинка альбому Сліпі Джона Естеса The Legend of Sleepy John Estes (1962) Джерело [1] Час створення 1962 Автор зображення невідомо Ліцензія Це зображення є обкладинкою музичного альбому або синглу. Найімовірніше, авторськими правами на обкладинку володіє видавець альбому (синглу) �...
The Chantic Bird First editionAuthorDavid IrelandLanguageEnglishGenreLiterary fictionPublisherHeinemann, LondonPublication date1968Media typePrintPages201 ppPreceded by– Followed byThe Unknown Industrial Prisoner The Chantic Bird (1968) is the debut novel by Australian writer David Ireland.[1] Plot summary The novel follows the story of a young, psychotic teenage boy living on the fringes of society in Sydney. His only interactions with the world are throug...
Indian TV series This article needs additional citations for verification. Please help improve this article by adding citations to reliable sources. Unsourced material may be challenged and removed.Find sources: Captain Vyom – news · newspapers · books · scholar · JSTOR (November 2015) (Learn how and when to remove this template message) Captain VyomCaptain VyomGenreActionScience fictionCreated byKetan MehtaStarringMilind SomanKartika RaneOpening theme...
Artikel ini tidak memiliki referensi atau sumber tepercaya sehingga isinya tidak bisa dipastikan. Tolong bantu perbaiki artikel ini dengan menambahkan referensi yang layak. Tulisan tanpa sumber dapat dipertanyakan dan dihapus sewaktu-waktu.Cari sumber: SMK Bina Prestasi Bangsa – berita · surat kabar · buku · cendekiawan · JSTOR SMK Bina Prestasi BangsaInformasiDidirikan2004AkreditasiBKepala SekolahDadan Herlana, S.Sos (Wakil Kepsek)Jurusan atau pe...
Kerk van Maria, Hulp der Christenen kan verwijzen naar: Maria Hulp der Christenen - titel van de Heilige Maria Kerken Kerk van Maria, Hulp der Christenen (Wiesbaden) - Duitsland Bedevaartskerk Maria Hulp der Christenen - Slovenië Basiliek Maria Hulp der Christenen - Italië Santa Maria Ausiliatrice in Via Tuscolana - Italië Maria Helpsterkerk (Berleur) - België Onze-Lieve-Vrouw-van-Bijstand-der-Christenenkerk (Sint-Niklaas) - België Bekijk alle artikelen waarvan de titel begint met K...
Defunct railway in England The Great Northern and Great Eastern Joint Railway, colloquially referred to as the Joint Line[1] was a railway line connecting Doncaster and Lincoln with March and Huntingdon in the eastern counties of England. It was owned jointly by the Great Northern Railway (GNR) and the Great Eastern Railway (GER). It was formed by transferring certain route sections from the parent companies, and by the construction of a new route between Spalding and Lincoln, and a n...
AEW World Tag Team Championship Los excampeones The Young Bucks con el diseño actual del campeonato.Nombre AEW World Tag Team ChampionshipPromoción All Elite WrestlingReinados oficiales 12Campeón actual Big Bill & Ricky StarksFecha de obtención 7 de octubre de 2023Fecha de creación 18 de junio de 2019Primer campeón SoCal Uncensored(Frankie Kazarian & Scorpio Sky) Récords Mayor número de reinado...
Electorial district in Tokyo, Japan Tokyo 20th District東京都第20区Parliamentary constituencyfor the Japanese House of RepresentativesPrefectureTokyoProportional BlockTokyoElectorate419,465 (as of 1 September 2022)[1]Current constituencyCreated1994SeatsOnePartyLDPRepresentativeSeiji KiharaTokyo 20th District (東京都第20区, Tokyo-to dai-niju-ku) is an electoral district of the Japanese House of Representatives. The district was created in 1994 as part of the move to single-me...
Questa voce sull'argomento calciatori sovietici è solo un abbozzo. Contribuisci a migliorarla secondo le convenzioni di Wikipedia. Segui i suggerimenti del progetto di riferimento. Andrej Černyšov Nazionalità Unione Sovietica Altezza 190 cm Calcio Ruolo Allenatore (ex difensore) Squadra Mohammedan Termine carriera 2001 - giocatore Carriera Squadre di club1 1987-1991 Dinamo Mosca73 (2)1992-1993 Spartak Mosca33 (3)1993-1994 Dinamo Mosca47 (2)1994-1996 St...
Voce principale: Società Sportiva Lazio. SS LazioStagione 1940-1941 Sport calcio Squadra Lazio Allenatore Géza Kertész[1], poi Ferenc Molnár[2], poi Dino Canestri[3] Presidente Andrea Ercoli Serie A14º Coppa ItaliaSemifinalista Maggiori presenzeCampionato: Flamini (30)Totale: Flamini (34) Miglior marcatoreCampionato: Piola (10)Totale: Piola (10) Stadiodel Partito Nazionale Fascista 1939-1940 1941-1942 Si invita a seguire il modello di voce Questa voce raccogl...
Den här artikeln omfattas av Wikipedias policy om biografier. Den behöver fler källhänvisningar för att kunna verifieras. (2020-03) Åtgärda genom att lägga till pålitliga källor (gärna som fotnoter). Uppgifter utan källhänvisning kan ifrågasättas och tas bort utan att det behöver diskuteras på diskussionssidan. Adam Jewelle Baptiste alias ADL född 8 februari 1973, är en svensk-amerikansk rappare.[1][2] Baptiste är född i Sverige med en svensk mamma och en pappa från Trin...






































{kind=link}










")
