Untuk menilai secara kasar taburan kebarangkalian pembolehubah tertentu dengan menggambarkan kekerapan pemerhatian yang berlaku dalam julat nilai tertentu.
Histogram ialah perwakilan anggaran taburan data berangka. Istilah ini mula diperkenalkan oleh Karl Pearson.[1] Untuk membina histogram, langkah pertama ialah mengelompokkan (bin) julat, yakni membahagikan keseluruhan julat nilai kepada satu siri selang—dan kemudian mengira berapa banyak nilai yang jatuh ke dalam setiap selang. Kelompok ini biasanya ditentukan sebagai selang berturut-turut dan tidak bertindih bagi sesebuah pemboleh ubah. Selang mestilah bersebelahan dan selalunya (tetapi tidak perlu) mempunyai saiz yang sama.[2]
Jika selang mempunyai saiz yang sama, segi empat tepat didirikan di atas selang dengan ketinggian berkadar dengan kekerapan — bilangan kes dalam setiap selang. Histogram juga boleh dinormalkan untuk memaparkan frekuensi "relatif". Ia kemudian menunjukkan perkadaran kes yang termasuk dalam setiap beberapa kategori, dengan jumlah ketinggian bersamaan 1.
Walau bagaimanapun, selang-selang tidak semestinya mempunyai lebar yang sama; dalam kes itu, segi empat tepat yang didirikan ditakrifkan mempunyai luasnya berkadar dengan kekerapan kes dalam tong.[3] Paksi menegak kemudiannya bukan mewakili kekerapan tetapi ketumpatan frekuensi — bilangan kes per unit pemboleh ubah pada paksi mendatar.
Oleh kerana selang bersebelahan tidak meninggalkan jurang, segi empat tepat histogram akan bersentuhan antara satu sama lain untuk menunjukkan bahawa pemboleh ubah asal bersifat berterusan (berselanjar).[4]
Histogram memberikan gambaran kasar tentang ketumpatan taburan asas data, dan selalunya dalam anggaran ketumpatan: menganggar fungsi ketumpatan kebarangkalian pemboleh ubah asas. Jumlah luas histogram yang digunakan untuk ketumpatan kebarangkalian sentiasa dinormalkan kepada 1. Jika panjang selang pada paksi-x semuanya 1, maka histogram adalah sama dengan plot frekuensi relatif.
Histogram ialah salah satu daripada tujuh alat asas kawalan kualiti.[5]
Histogram kadangkala dikelirukan dengan carta bar. Histogram digunakan bagi data selanjar, di mana selang mewakili julat data, manakala carta bar ialah plot bagi pemboleh ubah kategori. Sesetengah pengarang mengesyorkan bahawa carta bar mempunyai jurang antara segi empat tepat untuk menampakkan perbezaan.[6][7]
Contoh
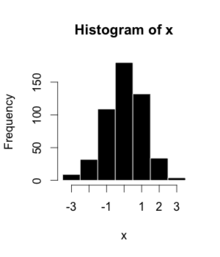
Ini ialah data untuk histogram di sebelah kanan, menggunakan 500 item:
Selang
Kiraan/Kekerapan
−3.5 hingga −2.51
9
−2.5 hingga −1.51
32
−1.5 hingga −0.51
109
−0.5 hingga 0.49
180
0.5 hingga 1.49
132
1.5 hingga 2.49
34
2.5 hingga 3.49
4
Perkataan yang digunakan untuk menerangkan corak dalam histogram ialah: "simetri", "terpencong ke kiri/kanan", "unimodal", "bimodal" atau "multimodal" (modal merujuk kepada bilangan "puncak").
Simetri, unimodal
Terpencong ke kanan
Terpencong ke kiri
Bimodal
Multimodal
Simetri
Poligon kekerapan
Poligon kekerapan contoh ini menunjukkan jisim sekumpulan tomato: jisim purata adalah sekitar 225 gram.
Daripada histogram, poligon kekerapan dapat diterbitkan dengan menyambungkan puncak lajur histogram. Khususnya, ia digunakan dalam mengesan bentuk taburan statistik dan membandingkannya dengan taburan kebarangkalian. Terdapat dua jenis poligon kekerapan lazim:
Poligon frekuensi mudah yang dibentuk dengan menyambungkan titik tengah atas lajur histogram dengan garis lurus.
Poligon kekerapan kumulatif bermula daripada histogram kumulatif. Dari asal set data, garis lurus dilanjutkan, naik dari had bawah selang seterusnya ke lajur.
Takrifan matematik
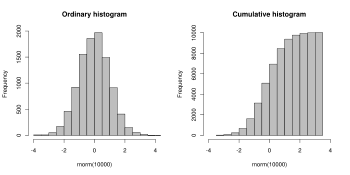
Histogram biasa dan kumulatif bagi data yang sama. Data yang ditunjukkan ialah sampel rawak 10,000 mata daripada taburan normal dengan min 0 dan sisihan piawai 1.
Data yang digunakan untuk membina histogram dijana melalui fungsi mi yang mengira bilangan pemerhatian yang termasuk dalam setiap kategori berbeza (selang). Oleh itu, jika kita biarkan n ialah jumlah bilangan cerapan dan k ialah jumlah bilangan selang, data histogram mi memenuhi syarat berikut:
Histogram kumulatif
Histogram kumulatif ialah pemetaan yang mengira bilangan terkumpul pemerhatian dalam semua selang sehingga selang yang ditentukan. Dengan itu, histogram terkumpul Mi bagi histogram mj ditakrifkan sebagai:
Bilangan selang dan lebar
Tiada bilangan selang yang "terbaik", dan saiz selang yang berbeza boleh mendedahkan ciri data yang berbeza. Pengelompokan data telah ada sekurang-kurangnya sejak karya Graunt pada abad ke-17, tetapi tiada garis panduan sistematik yang wujud[8] sehingga kerja Sturges pada 1926.[9]
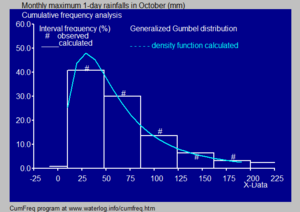
Histogram dan fungsi ketumpatan bagi taburan Gumbel.[10]
Aplikasi
Dalam hidrologi, histogram dan anggaran fungsi ketumpatan bagi data hujan dan luahan sungai, dianalisis dengan taburan kebarangkalian, digunakan untuk mendapatkan pandangan dalam tingkah laku dan kekerapan kejadiannya.[11] Satu contoh ditunjukkan dalam rajah biru.
Dalam banyak program pemprosesan imej digital, terdapat alat histogram, yang menunjukkan kepada anda taburan kontras/kecerahan piksel. Histogram kontras gambar.