![]() õ¯ Š¯ÇŠš ŠŠ¿õ¯ 1 ÚšÊÚ¡š¯´š¡ š õñŠÑÚ˜š õ瘚. 68-95-99.7 õñš¿ š¯¡õ° .
õ¯ Š¯ÇŠš ŠŠ¿õ¯ 1 ÚšÊÚ¡š¯´š¡ š õñŠÑÚ˜š õ瘚. 68-95-99.7 õñš¿ š¯¡õ° .
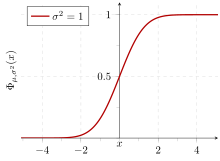 šš¡Àõ¯ 0õ°¥ ÚšÊÚ¡š¯´ 1š ŠÚŠ¡ š õñŠÑÚ˜š Šš ÚŠË .
šš¡Àõ¯ 0õ°¥ ÚšÊÚ¡š¯´ 1š ŠÚŠ¡ š õñŠÑÚ˜š Šš ÚŠË .
ÚšÊ Ú¡š¯´(̴̤ ÍÍñÛ, ššÇ: standard deviation, SD)Š Úçõ°šÏŠ´š ŠÑš¯š š Š ŠŠ šŠÈš š¯Ú˜ŠŠË¥ ŠÚŠÇŠ šš¿ŠÀ, ŠÑš¯š ššÇ šŠ š õ°Ýõñ¥ šÎ, ŠÑš¯š š õ°Ýõñ¥Ú õýš¥ŠÀ š šŠŠÊ. ÚšÊÚ¡š¯´õ¯ šššŠÀ Úõñ õ¯šš Š°ŠŠÊš õݯŠÎ˜õ¯ õ¯õ¿ŠÊ.[1] Úçõ°Úõ°¥ ÚŠË šš šÈ¥ŠÀ ÚŠË š ŠÑÚ˜, ÚŠË Š°š Ú¿š š¡Àš Š š¡õ瘊 šÊŠ°çšÏÚˋš š šˋŠŠÊ. õÇŠÀš Š¯Š¥ Šˆ´šÏŠ´š õñ¡ŠÎ˜šÊŠ˜¡šŠÀ ÚŠ°¡š ššÇ šÚŠý°š¥ŠÀ Úõ¡¯ÚŠŠ¯, Šˆ´šÏŠ´š ÚšÊÚ¡š¯´Š  (šõñ¡ŠÏ)ŠÀ, ÚŠ°¡š ÚšÊÚ¡š¯´Š
(šõñ¡ŠÏ)ŠÀ, ÚŠ°¡š ÚšÊÚ¡š¯´Š  (ššÊ)ŠÀ ŠÚŠ¡ŠÊ.[2]
(ššÊ)ŠÀ ŠÚŠ¡ŠÊ.[2]
Ú¡š¯´(deviation)Š õÇš¡Àõ¯šš Úõñ ŠŠ šÊšõ¯š Š¤ õýšÇŠÊ.
ŠÑš¯(variance)š õÇš¡Àõ¯šš Úõñ š Š¤ õ¯š š õ°ÝÚõ° , õñ¡õýš Šˆ´Š ŠÚ Ú š šýÇ õ¯₤šŠÀ ŠŠ š õç˜ÚŠÊ. šÎ, š¯´šÇõ¯š š õ°Ýš Úõñ šÇŠÊ. õÇš¡Àõ¯šš Úõñ š Š¤ õ¯š¡ Ú¡š¯´ŠË¥ Šˆ´Š ŠÚŠˋÇ 0šÇ ŠšÊŠ₤ŠÀ š õ°ÝÚÇš ŠÚŠÊ.
ÚšÊ Ú¡š¯´(standard deviation)Š ŠÑš¯š š õ°Ýõñ¥Ú õýšÇŠÊ. Ú¡š¯´ŠÊ(deviations)š š õ°ÝÚˋ(SS, sum of square)šš š£šÇšÏ õ¯š Úõñ š¿š¡ ŠÑš¯š šÝšÏŠÀŠÑÚ¯ ŠÊš š õ°Ýõñ¥ÚÇš šŠ Š´šŠÀ ŠÏŠÊšÇšÊš¥ŠÀš´ š£õýŠŠÊ.
Šˆ´ ÚšÊ Ú¡š¯´(population standard deviation) üŠ Šˆ´šÏŠ´š ÚšÊ Ú¡š¯´šÇŠÊ. Šˆ´ ŠÑš¯ ü2š š õ°Ýõñ¥š ššš õç˜ÚŠÊ.
ÚŠ°¡ ÚšÊ Ú¡š¯´(sample standard deviation) sŠ ÚŠ°¡š ÚšÊ Ú¡š¯´šÇŠÊ. ÚŠ°¡ ŠÑš¯ s2š š õ°Ýõñ¥š ššš õç˜ÚŠÊ.
š š
ÚŠË Š°š Xš õ¡¯Šõ¯ ![{\displaystyle \operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93) ŠË¥
ŠË¥  Š¥ Úš. šÇ Š Šˆ´šÏŠ´ Xš ÚšÊÚ¡š¯´
Š¥ Úš. šÇ Š Šˆ´šÏŠ´ Xš ÚšÊÚ¡š¯´  Š ŠÊšõ°¥ õ¯šÇ š šÚŠÊ.[3]
Š ŠÊšõ°¥ õ¯šÇ š šÚŠÊ.[3]
![{\displaystyle {\begin{aligned}\sigma &={\sqrt {\operatorname {E} \left[(X-\mu )^{2}\right]}}\\&={\sqrt {\operatorname {E} \left[X^{2}\right]+\operatorname {E} [-2\mu X]+\operatorname {E} \left[\mu ^{2}\right]}}\\&={\sqrt {\operatorname {E} \left[X^{2}\right]-2\mu \operatorname {E} [X]+\mu ^{2}}}\\&={\sqrt {\operatorname {E} \left[X^{2}\right]-2\mu ^{2}+\mu ^{2}}}\\&={\sqrt {\operatorname {E} \left[X^{2}\right]-\mu ^{2}}}\\&={\sqrt {\operatorname {E} \left[X^{2}\right]-(\operatorname {E} [X])^{2}}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2528934774f53f8c30b27ba52d6262052749385)
š Šõ°¥š šš õ¡¯Šõ¯š šÝšÏšÇ š˜šˋŠšŠÊ. ÚšÊÚ¡š¯´Š ŠÑš¯š š õ°Ýõñ¥õ°¥ õ¯š šŠ₤¡ŠË¥ õ¯šÏŠÊ.
Úçõ°š šÑš
Šš¥ õý§šÊŠË š¡ õý§š¯
õý§šÊŠË šÇ Šš¥Ú õý§š¯ ÚŠ°¡ ŠÇš šÇŠÊ Š°š¡ xõ¯ õ¯šÏŠ Šˆ´šÏŠ´šš ÚŠ°¡(sample)š ÚšÊÚ¡š¯´š šÑš š¿ sŠ ŠÊšõ°¥ õ¯ŠÊ.

- : ÚŠ°¡š ÚšÊÚ¡š¯´
 : Š°š¡
: Š°š¡ : ÚŠ°¡š Úõñ
: ÚŠ°¡š Úõñ  : ÚŠ°¡š Ú˜õ¡¯
: ÚŠ°¡š Ú˜õ¡¯ : šš¯´
: šš¯´
ŠÑŠˆ´ŠË¥ n-1ŠÀ ŠŠŠ šÇš Š ŠÑš¯š õ°š¯Ú Š Šˆ´Úõñ šÇ šŠ ÚŠ°¡ Úõñ š š˜šˋÚõ¡¯ ŠŠ˜¡š Šˆ´šÏŠ´š Ú¡š šÑš Š(biased estimator)šÇ ŠŠ₤ŠÀ, ŠÑš¯šÇ ŠÑÚ¡ šÑš Š(unbiased estimator)šÇ ŠŠŠÀ Úõ¡¯ šÚÇššÇŠÊ.[4] n-1š šš Š(degree of freedom)Š¥õ° Š°¡ŠÊ.[5]
õý§šÊŠË šÇ ŠÊŠË¡ õý§š¯
õý§šÊŠË š wŠ¥ Ú Š,  š¡ õý§š¯šŠ ÚŠ°¡(sample) ÚšÊÚ¡š¯´ sŠË¥ ŠÊšõ°¥ õ¯šÇ õç˜ÚŠÊ.[4]
š¡ õý§š¯šŠ ÚŠ°¡(sample) ÚšÊÚ¡š¯´ sŠË¥ ŠÊšõ°¥ õ¯šÇ õç˜ÚŠÊ.[4]

õ¯šÇ Š°Çõ¡¯
õ¯šÈ¥
|
|---|
| õ¯Š
| |
|---|
| š¯´Ú¡ | |
|---|
| Ú´ÚÇ | |
|---|
| šÏÚ | |
|---|
| š ŠŠÎ˜šÊÚ¡ | |
|---|


